撰稿 / 張鳳吟 (科學推展中心特約編輯)
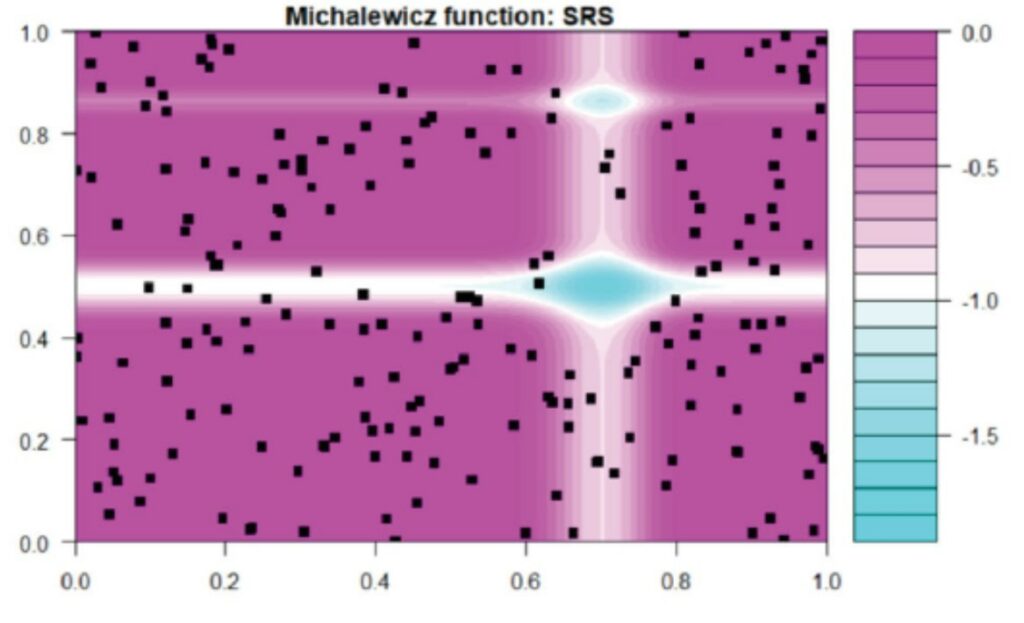
圖1、Michaelwicz函數的等高線圖(黑點代表SRS採樣的子數據)。
機器學習(machine learning)是人工智慧的一個分支,透過演算法將收集到的資料進行分類或預測訓練,建立”黑盒子”(black box)的輸入與輸出變數之間的關係,再以訓練出來的電腦模型對數據資料產生最佳預測。機器學習在科學上的應用相當廣泛,例如史上第一張由事件視界望遠鏡(EHT)所拍攝的M87黑洞影像,團隊後續利用機器學習的方法得到更詳細、塑形的影像結果。
然而,隨著技術發展,我們能取得的數據資料數呈爆炸性成長,超過先進統計方法與電腦能夠處理的範圍,這些限制導致計算期間數值的不穩定性,進而降低預測的準確度。為了能克服這個問題,近期統計學家發展出基於資料的最佳化子數據選擇(information-based optimal subdata selection,IBOSS)、拉丁超立方抽樣(Latin hypercube)等替代方法,期望在有限的時間與計算資源,選擇樣本數較小的子數據集,而可保留完整數據中的大部分資訊。中研院統計所助研究員張明中博士以原來處理全域最大/最小化的有效全域最佳化(efficient global optimization,EGO)演算法為基礎,提出一種能提供正確預測的新子數據集選擇法,此方法考慮了輸入特徵的幾何,以及輸出值的資訊。從數值模擬與真實數據的測試結果,張博士證明所提方法有更佳的預測能力,關於研究的細節與模擬結果發表於《計算與圖形統計期刊》(Journal of Computational and Graphical Statistics)[1]。
EGO演算法在1998年由Schonlau、Welch與Jones提出,原先是設計用於全域的最大與最小化。EGO的基本概念是根據目前的數據集計算改進函數(improvement function)的條件期望值,尋找下一個最有可能是極值的點,並將該點加入集合中,重複此一步驟直到迭代完成,由於計算過程會利用到搜尋點的資訊,因此比隨機的搜尋更有效率。張明中博士以EGO的概念與期望改進(expected improvement,EI)演算法為基礎,提出新的子數據選取準則。和傳統的EI不同,新準則以強化預測能力為目的,且子數據集\(\mathcal{D}_s\)外的輸出值可取得,新演算法可同時選擇多個預測性的資料點。
方法學介紹
張明中博士從高斯過程(Gaussian Process,GP)模型出發,假設一組很大的數據集\(\mathcal{D}={\mathbf{x}_i:i=1,\ldots,n}\),輸出為\(y\left(\mathbf{x}\right)=\eta\left(\mathbf{x}\right)+\epsilon(\mathbf{x})\),其中\(\eta\left(\mathbf{x}\right)\)為高斯過程回歸的輸出,\(\epsilon(\mathbf{x})\)為隨機誤差。\(f(\mathbf{x})\)為輸出的真正數值,對於決定性(deterministic)的過程\(y\left(\mathbf{x}\right)=f\left(\mathbf{x}\right)\),反之,\(y\left(\mathbf{x}\right)=f\left(\mathbf{x}\right)+\ \epsilon(\mathbf{x})\)。對給定的\(k\geq1\),預測性模型應該與任何k維的未觀測輸入\(\mathbf{x}_{i1,\ldots,}\mathbf{x}_{ik}\)的真實輸出非常接近。定義改進函數\(I(\mathbf{x}_{i1,\ldots,}\mathbf{x}_{ik})\)為\(\eta\left(\mathbf{x}\right)\)與\(f\left(\mathbf{x}\right)\)在\(\mathbf{x}_{i1,\ldots,}\mathbf{x}_{ik}\)的偏差,只要I是大的,就把\(\mathbf{x}_{i1,\ldots,}\mathbf{x}_{ik}\)加入目前的子數據集\(D_s\)中。根據這樣的思維,張明中博士的新演算法步驟如下:1. 先決定子數據集大小M,利用非監督式(unsupervised)方法,如簡單隨機抽樣(SRS)或SPlit法,來選擇初始的子數據集大小\(\mathcal{D}_0\)(例如0.3M)。2. 設定\(R_{pred}^2\)(\(\mathcal{D}_s\))=1-\(\frac{MSE(D_s)}{MSE(D_0)}\)為評估\(\mathcal{D}_s\)預測表現的量,其中\(MSE(\mathcal{D}_s)\)代表誤差的均方差,如果\(R_{pred}^2\)(\(\mathcal{D}_s\))小於0代表\(\mathcal{D}_s\)比\(\mathcal{D}_0\)的預測更差。定義\(a_s\)為加入子數據集\(\mathcal{D}_s\)的數據點數,設\(a_s=1\)與\(\mathcal{D}_1=\mathcal{D}_0\),當\(R_{pred}^2(\mathcal{D}_s)\geq R_{pred}^2(\mathcal{D}_{s-1})\),增加\(a_s\) (例如\(a_s\rightarrow2a_s\));反之減少\(a_s\) (例如\(a_s\rightarrow a_s/2\)),如果\(\left|\mathcal{D}_s\right|+a_s>M\),則設\(a_s=M-\left|\mathcal{D}_s\right|\)。3. \(k=a_s\),當\(\mathcal{D}-\mathcal{D}_s\)中所有k大小數據點的改進函數期望值\(E\left(I(\mathbf{x}_{i1,\ldots,}\mathbf{x}_{ik})\middle| y\right)\)最大,\({\mathbf{x}_{i1,\ldots,}\mathbf{x}_{ik}}\)加入\(\mathcal{D}_s\),更新\(\mathcal{D}_{s+1}=\mathcal{D}_s\cup{\mathbf{x}_{i1,\ldots,}\mathbf{x}_{ik}}\)。重複2、3步驟直到達到預定子數據集大小M或是穩定的\(R_{pred}^2\)。根據張明中博士所推導的結果,新方法學的計算複雜性(指計算花費時間)為\(O\left(nM\right)+O(M^3)\),遠小於直接擬合完整數據的\(O\left(n^3\right)\)。
數值測試
張明中博士將新方法學應用在數個函數與真實數據中,並和其它演算法做比較。圖1為Michaelwicz函數\(f_m\left(x\right)=-\sum_{j=1}^{2}\sin{\left(\pi x_j\right){sin}^{20}(j\pi x_j^2)}\)的等高線圖(contour plot),其中黑點為SRS所採樣的子數據集,可看到僅有少數黑點出現在產生函數解較起伏的區域,無法正確預測函數的真正結構。
應用張明中博士所提的新方法,M設為80 (n為1000),\(a_s\rightarrow1\)(每次增加一點),比較Joseph 與 Mak的監督式數據壓縮法(Supercom) (2021),結果如圖2,兩種方法皆在產生高輸出變化的區域採樣較多的資料點,不過張博士的新方法在藍色區域比Supercom有更多的資料點,下圖為利用兩個子數據擬合預測的等高線圖,新方法的產生的結果較佳。
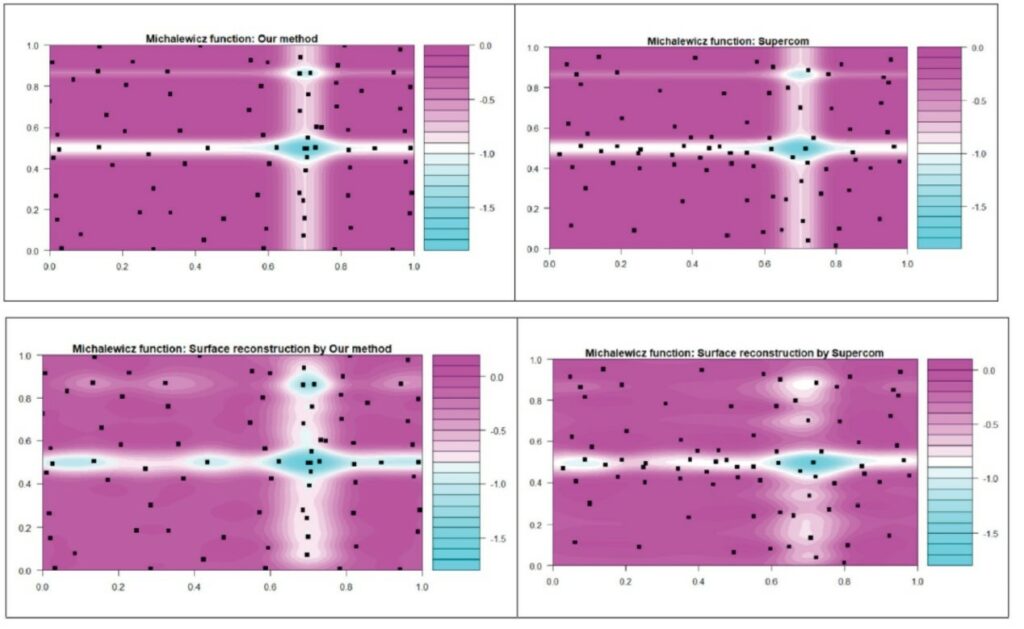
圖2、(上) Michaelwicz函數等高線圖與不同方法取樣的子數據。(下) 不同子數據集所預測的等高線圖。
圖3為高維( d=8)的Drop-Wave函數,n=100,000,M=1000,設定當\(R_{pred}^2(\mathcal{D}_s)\geq R_{pred}^2(\mathcal{D}_{s-1})\),\(a_{s+1}=2a_s\),反之\(a_{s+1}=\left\lceil a_s/2\right\rceil\),比較Supercom法取樣數據點與擬合的等高線圖的結果如下,新方法學有較好的預測能力:
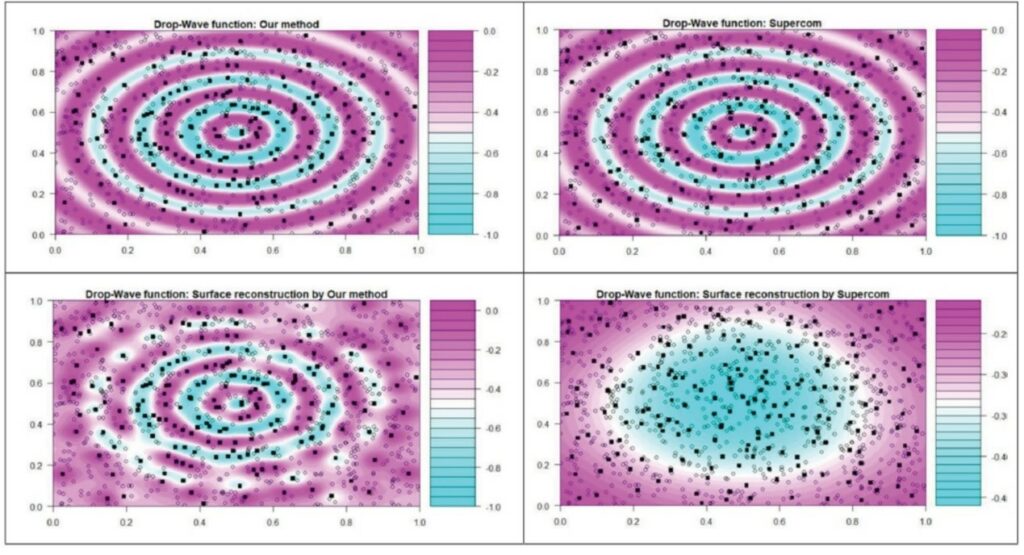
圖3、(上) Drop-Water函數等高線圖與不同方法取樣的子數據。(下) 不同子數據集所預測的等高線圖。
圖4為不同方法學(完整數據、新方法學、SRS、Supercom)在函數與真實數據應用的均方根預測誤差(RMSPEs),所提之新方法學較低的誤差值。
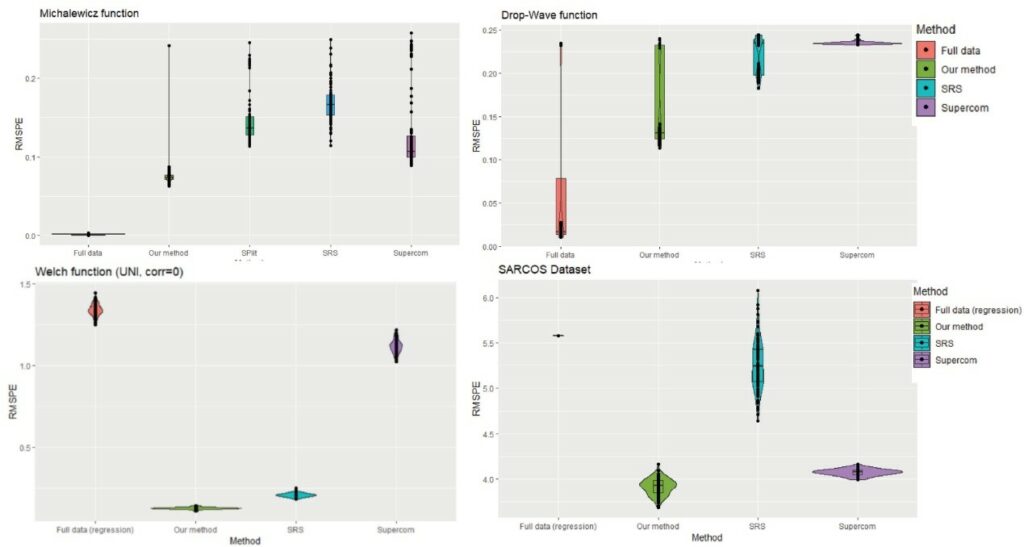
圖4、為不同方法學在函數與真實數據應用的均方根預測誤差。
許多統計方法無法有效應用在大型的數據集,張明中博士表示,雖然他的新方法在一些範例的表現超越其它方法,但這個方法是特別針對決定性的電腦模型,不代表對所有模型都普遍較好。未來的研究方向,將包括設定最佳化的子數據集增加大小為最佳化,以及發展此方法之非母數(nonparametric)版本,來因應真實世界的輸入-輸出關係。
參考文獻
[1] Ming-Chung Chang*, Predictive subdata selection for computer models, Journal of Computational and Graphical Statistics, 32, 613-630(2023).