撰稿 / 陳宣豪 (科學推展中心特約編輯)
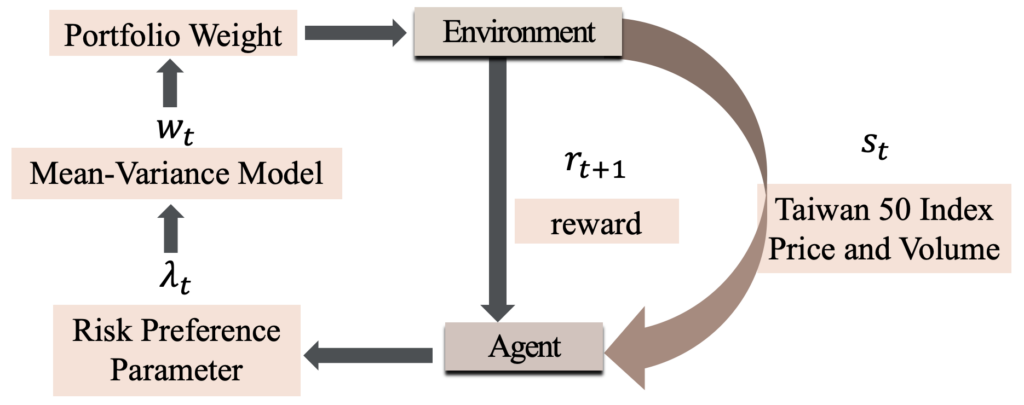
圖1. 動態風險偏好的強化學習框架
依訓練資料、產出判別的過程與結果不同,機器學習大致上可以分為三類:監督式學習(Supervised Learning)、非監督式學習(Unsupervised Learing)和強化學習(Reinforcement Learning)。在一般投資環境中,較常使用監督式學習,常用於股票價格預測或其他資產價值,不過該方法過於依賴固定樣本且未考慮順序關係,相對而言,強化學習透過獎勵來促進當前環境中的最佳決策,且決策會隨著環境、時間變化而同步調整,代表一個多周期的決策過程,較監督學習更適合投資決策研究。
強化學習主要強調系統透過與一個動態(dynamic)環境不斷重複地互動,來學習如何正確地執行一項任務,即透過錯誤嘗試(trial-and-error)方式,在沒有人類干預或明確執行程式下,基於環境而行動以取得最大化的預期利益。目前最著名的強化學習案例就是AlphaGo,史上第一支打敗人類圍棋比賽世界冠軍的電腦程式。
整合強化學習的傳統投資模型
最佳資產配置(Optimal asset allocation)對於投資者每日面對錯綜複雜且不斷變化的金融市場至關重要,1952年Markowitz就提出平均數-變異數投資組合模型(Mean-variance model),開創了投資組合理論,現今不論是財務研究或實務投資,變異數或標準差是廣被一般大眾所使用的風險衡量方式,不過變異數或標準差並非唯一的風險衡量方式,它較適用於單次決策,因為若投資組合僅考慮預期收益和風險,其實並不符合現實狀況。
中央大學數學系陳亭甫助理教授及其團隊,在強化學習的框架中構建基於市場數據的投資環境,包含台灣50指數的價格及數量等數據,來衡量台灣金融市場的波動性,並整合平均數-變異數模型來建構投資組合,使用滑動視窗(moving window)來訓練及測試,模型透過團隊設計的獎勵函數進行學習。同時比較強化學習動態投資組合的模型與其他模型在各種市場條件下的表現和投資風險,在不同時間點,透過強化學習的動態優勢來調整風險偏好參數,以解決風險偏好參數的問題,而投資組合式基於平均數-變異數模型,也確保其在經濟理論的表現。這一系列決策則可用馬可夫決策過程(Markovian decision processes,MDP)描述,透過函數最大化來計算出對應獎勵,試圖訓練一個代理人(agent)來執行適當的策略:透過選擇不同的風險趨避程度參數,在市場上漲時追求投資組合的最大收益,在市場下跌則極小化投資組合的風險。
研究團隊表示,其研究框架有兩項優點:第一優點是容易實踐,沒有使用複雜的強化學習框架;第二個優點是結果易於解釋,因為投資組合是基於具經濟理論的平均值-變異數模型,風險偏好參數則透過強化學習決定。最後研究結果指出,強化學習結合平均值-變異數模型的投資組合,表現優於台灣50指數或具固定風險偏好的投資組合,並且在市場呈現大幅上漲或下跌的期間,訓練後的模型能夠更好的準確性,讓獎勵函數產生更高的回報。