撰稿 / 鄭淳澧 (科學推展中心特約編輯)
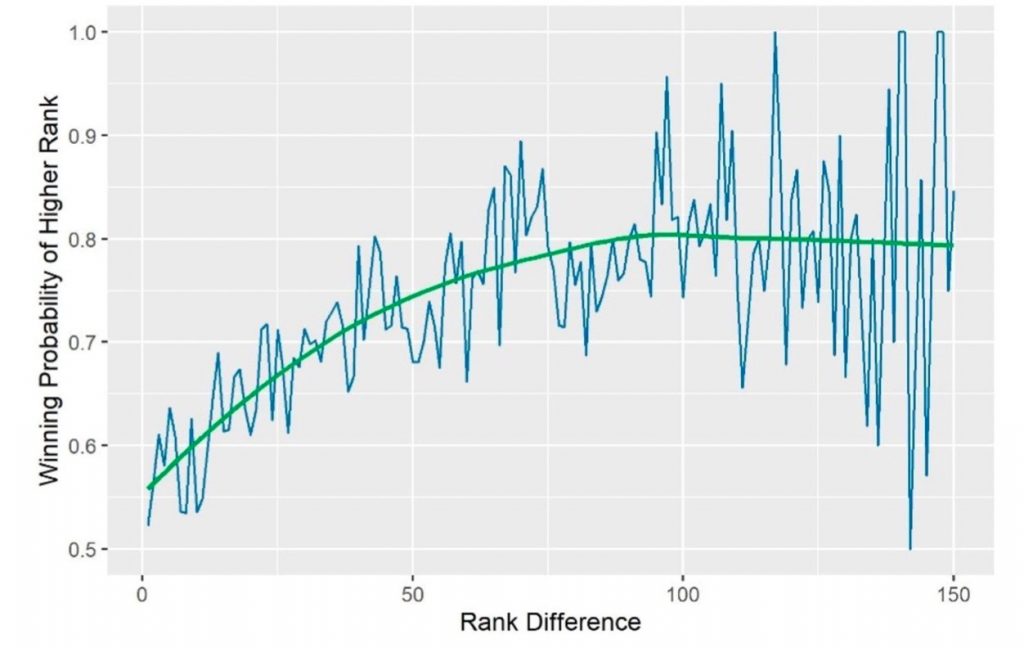
圖1、LOESS(局部加權)迴歸分析選手排名差距與其勝率
近年AI(人工智慧)、ML(機器學習)、DL(深度學習)等議題的廣為流傳,一般民眾多半知道大數據應用層面的廣泛,在電腦飛快發展的時代,無論組織或個人都可透過現有的資訊來創造更多機會,例如企業可透過數據分析找到新藍海,以尋求更高的利潤。運動賽事當然也是大數據的重要應用之一,除了可用於選手訓練和挑選外,預測個人的運動表現更常是研究的探討議題。
IBM提出的大數據具有四個特點,或說指導原則 4V:Volume(資料量)、Velocity(速度)、Variety(多樣性)、Veracity(真實性)。無論導入何種模型,區分信噪(signal & noise)通常是非常關鍵的步驟,以科學實驗的變因來說明,如果能夠了解變因對實驗造成的影響,像是哪些變因需要控制不變、哪些變因需要操縱改變等,通常就能獲得想要的結果(因變數)。
資料分析的前置作業之一為蒐集數據,蒐集數據可以想像成情報收集。然而,即便想盡辦法收集所有相關情報,將所有變量都導入模型卻未必可行,因為不是所有數據都有助於解析結果,比方說低度相關與高度相關的兩個變量,通常會採用高度相關作為預測下場賽事的變量。
網球大滿貫賽事(澳洲、法國、溫布頓、美國公開賽)是全球最重要的年度網球賽事,單打比賽會有128名選手參與,採單淘汰制,也就是需要127場比賽才能決定冠軍。政治大學余清祥教授等人在此研究中採用Glicko模型,並利用EDA(探索式資料分析)引入新的變量,評估可否提高模型的預測準確性。Glicko模型是一種在職業西洋棋中的貝氏(定理)分析方法,余教授以此模型決定新變量,接著將所有變量以兩兩配對比賽的方式套入迴歸分析,再透過交叉驗證計算預測模型的誤差。在這個研究中,透過下列算式以Glicko評分系統決定每位選手的RD變量:
![]()
其中RD是評分標準差,代表評分的可變與不確定性,RD0是球員的初始RD,RDold是球員的前一次比賽的RD,c是常數,t則代表上次比賽以來的評分週期。隨著每位選手參賽紀錄的累積,個人比賽實力的不確定性會下降,若選手從來沒參加過比賽,不確定性通常較高,此時初始的評分變量通常被設為1500,評分標準差為350,常數c為10。接著採用EDA選擇較為合適的變量加入迴歸模型,本研究考慮的變量包括球員的居住地、年齡、職業生涯初始年、慣用手,以及2000-2019年的排名與積分。
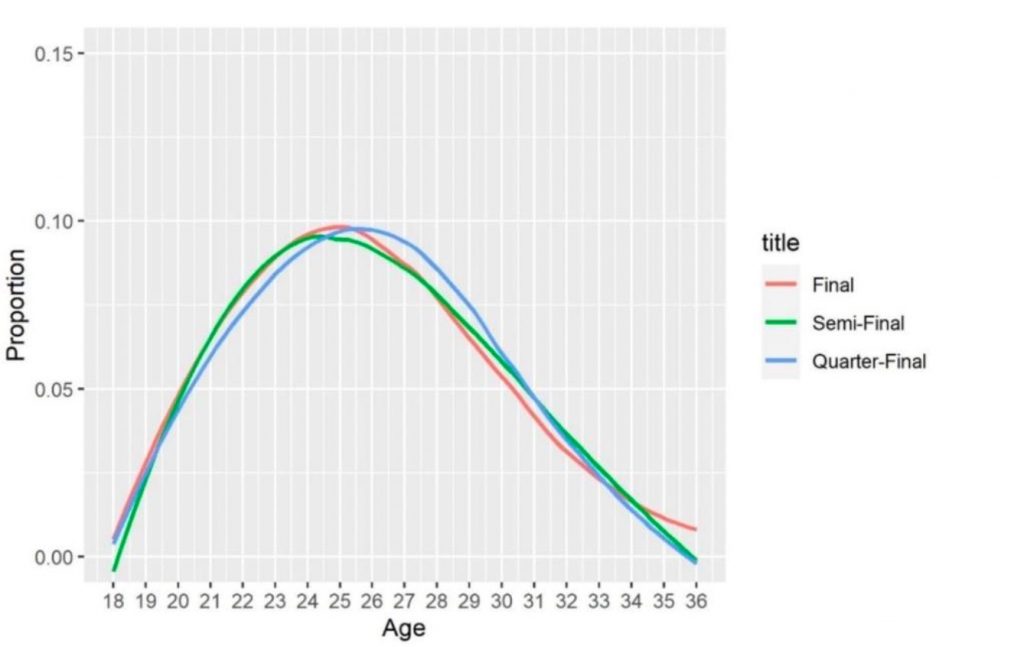
圖2、晉級網球大滿貫賽事決賽、準決賽、八強賽的球員年齡結構
圖2. 顯示晉級決賽、準決賽、八強賽的球員年齡結構非常相似,三種情況的峰值約在25歲。圖1. 採用LOESS(局部加權)迴歸分析,可以看見選手排名差距達80時,勝率大約為八成,圖形中也顯示了高排名選手的波動小,低排名的波動大。換言之,若想涵蓋更多的變量來提升預測的準確性,選手排名是非常重要的因素,因為透過選手排名可預期是否能夠進入後面幾輪比賽。
藉由累積密度函數更能看出排名變量蘊含的重要資訊。逆分佈函數的定義為:
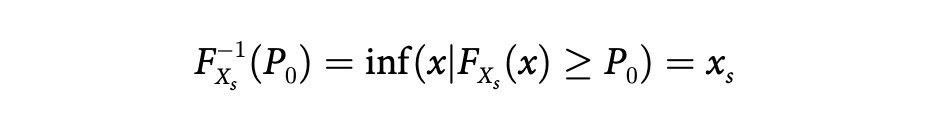
其中FXs(x) 是 Xs累積密度函數,P0為所選擇的百分位,Xs是進到s輪的最低排名,s = 1, 2, 3, … , 7,其中5、6、7、7+分別表示八強賽、準決賽、決賽和冠軍。表1.為採用P0 = 0.8 的結果,可以看出贏得冠軍的80% 為排名最佳的前五名選手,進到決賽的80%為排名前九名的選手,P0 = 0.8是經驗法則,或是俗稱「20/80定律」。
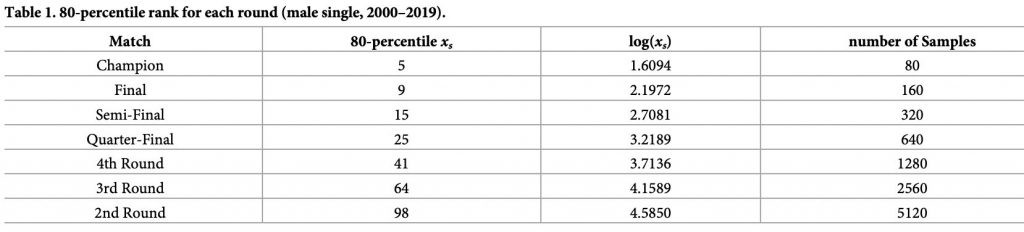
表1、2000-2019年男子大滿貫網球每一輪賽事中P0 = 0.8 的結果
表2.跟表3.分別表示ATP(職業男網)、WTA(職業女網)在各種模型下的預測準度,準確性是以moving-window(移動視窗)的交叉驗證計算,以四年訓練資料預測接下來之後兩年資料的結果,以此類推。其中男女選手在硬地與草地的預測準確率之不同,兩個表格也顯示複雜的模型如SVM(向量機)、Neural Network(神經網路)、LightBGM(輕量梯度機)的預測準度未必更準確,分類結果以Glicko模型最佳。
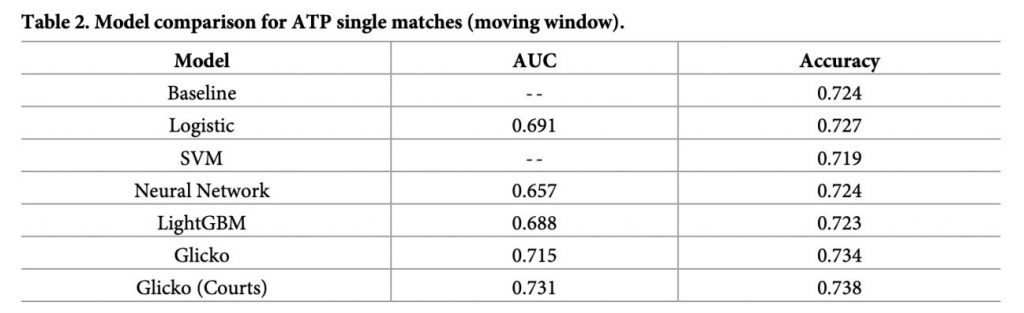
表2、ATP(職業男網)在各種模型下的預測準度
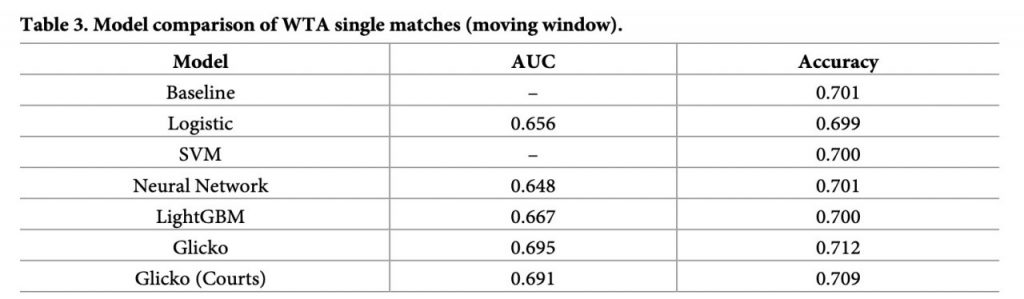
表3、WTA(職業女網)在各種模型下的預測準度
余清祥教授等人以Glicko模型引入新的變量,Glicko模型採用貝氏定理更新選手的重要資訊;接著使用EDA工具選擇較為適合的變量,代入各種統計及機器學習模型,並透過交叉驗證評估分類結果,最終發現Glicko模型對預測網球賽事的準確度高於其他模型。
而此實驗的目的在於試圖增強數據模型的功能,並藉由EDA的幫助找出重要變量,例如選手排名潛藏許多重要的訊息。透過EDA和Glicko模型,我們發現結合專家意見與量化分析是另種進行方式,這與單純依賴機器學習大有不同,因機器學習通常不加入專業運動領域知識,沒有考慮到人類智慧累積的優點,但專家意見往往又難以數據化,未來期望可以努力朝人類智慧與人工智慧中間找到平衡點。